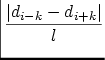Sous-sections
L'opération de segmentation d'un trait consiste ŕ détecter les différents segments
géométriques que représente un trait ŕ main levée (voir section 4.4.3). La figure
A.3 présente deux exemples de traits et leurs décompositions, les deux cas que l'on peut
rencontrer lors d'un dessin ŕ main levée: un trait représente un segment (voir figure
A.3(a)) ou un trait représente plusieurs segments (voir figure A.3(b)).
Figure A.3:
Segmentation de traits. Cette figure représente des
traits dessinés (en noir) et les segments qu'ils représentent (en rouge).
![\begin{figure}\setcounter{subfigure}{0}
\begin{center}
\subfigure[Un trait repr...
...ts.]{
\includegraphics[width=.47\textwidth]{segs2}}
\end{center}
\end{figure}](img143.png) |
L'expérience que nous avons du dessin d'architecte et l'étude que nous avons menée ont montrées que
le premier cas est le plus fréquent, un trait continu représente souvent un seul segment. Dčs lors,
l'opération de segmentation est on ne peut plus simple: le segment correspondant au trait est
composé par les deux points extręmes de celui-ci (A et B dans la figure A.3(a)). Mais, dans
notre paradigme de dessin ŕ main levée sans contraintes, nous ne pouvons pas écarter le second cas
que l'on rencontre tout de męme plus ou moins fréquemment chez les dessinateurs (selon leur style ou
leurs habitudes).
Dans ce cas général, le principe de la segmentation est de détecter, parmi les points capturés lors
du tracé, ceux qui vont devenir les extrémités des segments (A, B, C et D dans la figure
A.3(b)). Ces points sont appelés points critiques ou coins. Comme nous
l'avons déjŕ évoqué dans ce mémoire, de nombreuses méthodes ont été proposées pour déterminer ces
points dans les domaines de l'analyse d'images ou de l'interprétation temps réel. Nous ne
détaillerons donc que celle que nous avons employée, combinant les données de courbure du trait et
de vitesse de dessin en chaque point pour déterminer cette segmentation trait par trait.
Car en effet, beaucoup de travaux ont montré que le trait présente en ses points caractéristiques
une courbure plus importante que les autres. C'est sur le calcul et l'analyse de cette donnée que
sont basées la plupart des méthodes de détection. Toutefois, des variations trop minimes et lisses
du rayon de courbure, ou des changements de direction trop fréquents peuvent entraîner la détection
de «faux-positifs» ou l'omission de points. C'est pourquoi, dans une optique de détection temps
réel oů les information temporelle sont disponibles, Tevfik SEZGIN a proposé de combiner cette
information de courbure avec la vitesse de dessin. Ŕ partir des résultats proposés dans
[Lacquaniti et al.1983] et de mesures de la diminution de la vitesse de dessin au voisinage des points
critiques, il a proposé dans [Sezgin et al.2001] une méthode hybride que nous avons reproduite pour la
segmentation des traits dans SVALABARD.
Nous en donnerons ici les grandes lignes. Pour des justifications plus approfondies et des résultats
plus précis de cette méthode, nous renvoyons le lecteur aux publications dont elle est tirée
[Sezgin et al.2001,Sezgin2001]. Le principe général est de calculer, pour chaque point enregistré du
trait, une «mesure de certitude» qui va représenter son aptitude ŕ ętre un point critique du
trait. Ensuite, il faut constituer un ensemble de solutions hybrides et choisir la meilleure d'entre
elles.
Courbure.La premičre mesure est exprimée par la grandeur mesurée de la courbure
au voisinage de chaque point pi:
Formule A..1
Calcul de la mesure de courbure au voisinage d'un point.
oů l est la longueur de la courbe entre les points pi-k et
pi+k, k est un entier qui définit la taille du voisinage considéré autour du point. Les
valeurs di représentent la direction de la courbe au point pi (l'angle formé par la tangente
au trait au point donné avec l'axe des x).
Le calcul de la tangente soulčve des problčmes de précision, résolus dans la méthode originale
par l'utilisation d'une approximation numérique discrčte: l'ODR (pour Orthogonal Distance
Regression). Dans notre implémentation, nous avons utilisé un simple filtrage moyen des points qui
assure une distance minimale entre deux points consécutifs pour un calcul simple par la formule:
d = arctan(Δx, Δy)2 (Δx et Δy représentent le changement de position
relatif entre deux points). Bien que moins précis que la méthode originale, les résultats sont tout
de męme satisfaisants A.2. Enfin, cette
mesure est normalisée pour obtenir des valeurs dans l'intervalle [0, 1] pour chaque point.
Vitesse.La seconde mesure correspond ŕ une mesure du ralentissement du stylet en
chaque point pi, exprimée par:
Formule A..2
Calcul du ralentissement en un point.
1 -
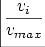
Cette mesure donne aussi des valeurs comprises dans l'intervalle [0, 1].
Ces premiers calculs donnent donc deux ensembles de points Fc et Fs, obtenus et triés par
ordre décroissant ŕ partir des données respectives de courbure et de vitesse. Une premičre solution
hybride H0 est alors construite par intersection de Fc et de Fs (le premier et le dernier
point du trait, ainsi que les points de męme ordre dans Fc et dans Fs).
Ensuite, deux nouvelles possibilités sont construites ŕ partir de la solution précédente en lui
ajoutant comme nouveau point caractéristique:
- Le meilleur point candidat des données de vitesse. On obtient
H'i = Hi∪{ps}.
- Le meilleur point candidat des données de courbure. On obtient
H''i = Hi∪{pc}.
Ŕ chacune de ces solutions est associée une mesure de pertinence, basée sur un calcul d'erreur aux
moindres carrés: la somme moyenne des carrés des distances de chaque point du trait S ŕ la
solution.
Formule A..3
Calcul de l'erreur pour une solution.
εi =
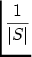
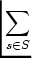 ODSQ
ODSQ(
s,
Hi)
A.4
Ainsi, des deux solution possibles (vitesse ou courbure), celle de plus faible erreur (la plus
proche du trait original) est conservée et devient Hi+1. Les itérations continuent alors
ŕ partir de cette solution jusqu'ŕ ce que tous les points candidats aient été utilisés afin de
construire un ensemble de solutions hybrides.
Dčs lors, le choix de la segmentation ŕ conserver parmi l'ensemble construit nécessite d'établir un
compromis entre l'augmentation du nombre de points et la diminution de l'erreur. La solution retenue
et justifiée par l'auteur de cette méthode est de conserver comme unique solution celle dont
l'erreur est en dessous d'un seuil fixé, avec le moins de points possibles. Dans notre
implémentation, nous avons choisi de rendre ce seuil d'erreur paramétrable afin de pouvoir
simplement et interactivement ajuster la précision de l'algorithme.
L'algorithme simplifiéA.5 A.1 donne une
vue plus synthétique de ce traitement et de ses étapes.

stuf
2005-09-06